Cassandra Data Model Basics

Data. Model. What an odd combination of words. To someone outside of the world of I.T., it doesn’t make much sense. But to those people that have written software or attempted to store information, it’s a phrase all too often discussed. A data model, as defined by wiki, “is an abstract model that organizes elements of data and standardizes how they relate to one another and to properties of the real world”.
Data modeling has evolved over the years as technology has changed. The requirements of today’s data model reflect the structure of the machine(s) that it runs upon. When the norm was a mainframe or a single machine, then a relational database was efficient. However, today’s norm is to have a global network of machines that can all provide the same data as efficiently as if it were a single machine.
Enter Apache Cassandra. The goal is to have the most efficient way of coordinating changing distributed data. The purpose of this post is to discuss how to model your data for evenly distributed storage and efficient retrieval using Cassandra.
How Cassandra stores data
Cassandra is a key-value store. Data is organized into rows of multiple columns/values. Rows belong to a single node and are replicated to other nodes in the cluster. The cluster is organized into a ring of nodes with each node having an equal part of the of hash values. Each row’s key is hashed to determine where in the ring the row’s data should be stored.

Visuals are always the best way to get a point across, in my opinion. So imagine that we have a four node Cassandra cluster. It has a single keyspace with a replication factor of three. In that keyspace, there is a single table. For every record that is inserted, Cassandra will hash the value of the row key in that table to determine which nodes are responsible for that row. For simplicities sake, let’s use 0-100 as possible hash values. In reality, the hash will be something like a 128-bit (or larger) value, but examples are so much harder when you have to reference that nonsense. Node 1 is responsible for hash values 1-25, Node 2 is responsible for hash values 26-50, and so on.
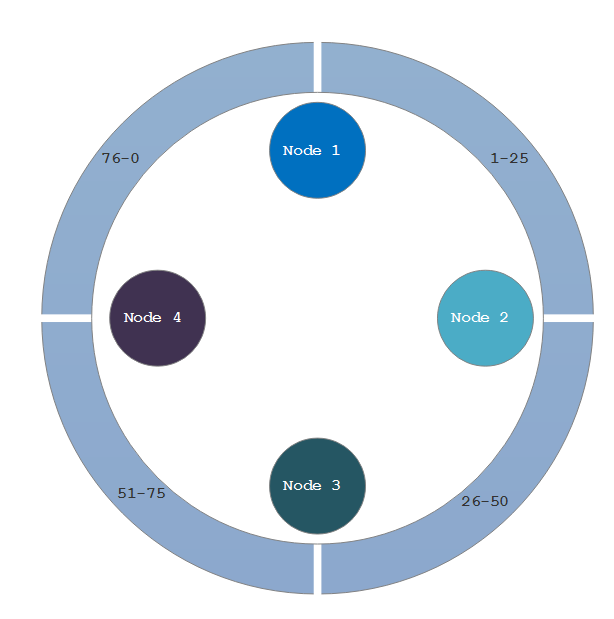
The first row that we insert gets hashed. Let’s say that the hash has a value of 72. Using the below diagram, that row will belong to Node 4 and will be replicated to Nodes 1 & 2. Replication always goes clockwise in a cluster. Then we add another row to the table. It’s hash has a value of 31, which will belong to Node 2, 3, & 4. We keep adding records and the hashes are figured and each of the nodes randomly are assigned rows to maintain. That’s the entire concept behind how Cassandra stores data.
Goals for data placement
The hope is that every node in your cluster has an equal responsibility for maintaining a portion of the entire data set. When determining what each table’s primary key will be, you want to make sure that the key’s cardinality is high enough to not cause hot spots on any of the drives. When it comes to reading data off the disk, you will want to be seeking as few partitions as possible.
It would be horrible if half of your inserted values had a hash value between 1-25. If that were to happen, then Nodes 1, 2, & 3 would have a much larger portion of the responsibility for the data set. When reading those rows back out from Cassandra, those 3 nodes would be doing a multiple more of work. With only 4 nodes, it may not seem like a huge deal, but imagine a cluster of 16, and 3 nodes were overly loaded.
The CPUs on those machines would be working harder which would lead to higher read latencies, which may lead to block or dropped mutations. Horrible stuff, I know. All of which would have been preventable with the correct primary key definition in the data model.
Start with your query
The best advice that I ever received for designing a good data model is to “Start with your query”. Think about how you are going to be presenting your data to your user. Then think about how you’ll search for that data. What you’re searching for should naturally be your primary key and the information you plan on presenting should be your columns. That’s it. Traditional, relational data models will have you think about third, fourth, etc normal forms before you ever even thing about what the UI will do. That is the complete opposite of designing data models in Cassandra. Remember, “Start with your query”.
Don’t cross the hashes
When retrieving your data, you want to target as small a hash value as possible. Remember the rows we inserted in the above example. The first row had a hash value of 72 and the second row had a hash value of 31. If we issues a read request that asked for those 2 rows to be returned, then we would potentially be asking all 4 nodes in the cluster to respond. It’s better to ask for smaller sets of data that are local to single nodes. Issue a pair of read requests; one for each of the 2 rows you’re after. It’s better to have 2 requests retrieving single rows, rather than single requests retrieving multiple rows. This may not seem like that big of a deal with 2 rows, but what if it were an IN clause with 20 or 50 rows. A simple request becomes a big drain on resources.
Misconceptions
A misconception that I see is that people think that they should always try to make tables hold way more information than is necessary. The belief that a table should be used for many, many searches. The truth is that having many similar tables with similar data is a good thing in Cassandra. Limit the primary key to exactly what you’ll be searching with. If you plan on searching the data with a similar, but different criteria, then make it a separate table. There is no drawback for having the same data stored differently. Duplication of data is your friend in Cassandra.
Another misconception is about conserving your writes. Cassandra writes out data to disk so much faster than any traditional relational database ever could. Because of this writes are cheap and should be used as often as possible. Don’t try to cache up data to send to the database for storage all at once. If you have a portion of the data, write it out. Don’t wait for the entire recored to be received from the application. If you need to store the same piece of data in 14 different tables, then write it out 14 times. There isn’t a handicap against multiple writes.
Conclusion
This post should help you understand a bit more about the basics of Cassandra data models. I’ve covered how you should distribute & retrieve your data, and common pitfalls to avoid. With a bit of trial and error, you’ll be able to begin writing your own data models.