Cassandra Partitioning & Clustering Keys Explained
Primary and Clustering Keys should be one of the very first things you learn about when modeling Cassandra data. Most people coming from a relational background automatically think, “Yeah, I know what a Primary Key is”, and gloss right over it. Because of this, there always seems to be a lot of confusion around the topic of Primary Keys in Cassandra. With this post, I will try to demystify the confusion. I will cover what the different types of Primary Keys are, how they can be used, what their purpose is, and how they affect your queries.
For this post, I will be using CrossFit gyms as my subject matter. The cool thing about CrossFit gym names, in a database sense, is that they are completely unique. No two gyms are allowed to have the same name.
The Basics
Primary Keys are defined when you create your table. The most basic primary key is a single column. A single column is great for when you know the value that you will be searching for. The following table has a single column, gym_name, as the primary key:
CREATE TABLE crossfit_gyms (
gym_name text,
city text,
state_province text,
country_code text,
PRIMARY KEY (gym_name)
);A single column Primary Key is also called a Partition Key. When Cassandra is deciding where in the cluster to store this particular piece of data, it will hash the partition key. The value of that hash dictates where the data will reside and which replicas will be responsible for it.
Partition Key
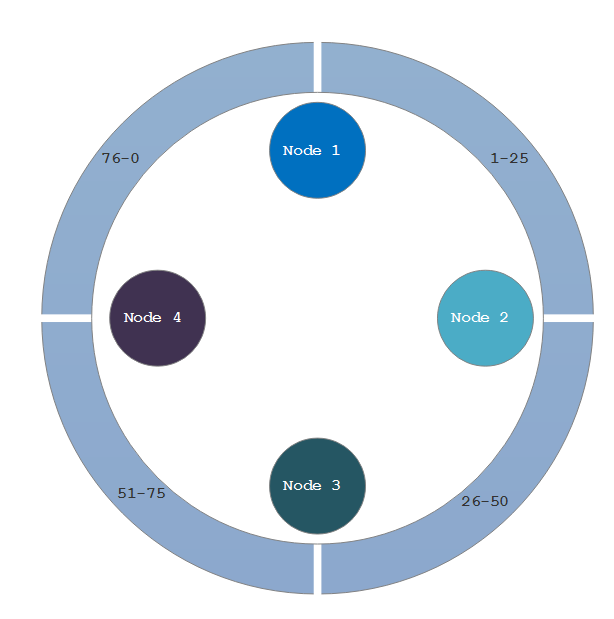
The Partition Key is responsible for the distribution of data amongst the nodes. Let’s look back to an earlier post on Cassandra Data Model Basics, in which I described a four node cluster, as shown below. For simplicities’ sake, let’s assume hash values are between 0-100. When we insert the first row into the crossfit_gyms table, the value of gym_name will be hashed. Let’s also assume that the first record will have a hash of 34. That will fall into the values that Node 2’s partition is assigned. So the value of the Partition Key, 34, indicates the partition, 26-50, in the cluster/ring that the piece of data will be stored. Makes sense, huh?
Compound Keys
But wait, there’s more! Primary keys can also be more than one column. A multi-column primary key is called a Compound Key. The following example is a similar same table as above but changes the primary keys so that you can search a little more widely.:
CREATE TABLE crossfit_gyms_by_location (
country_code text,
state_province text,
city text,
gym_name text,
PRIMARY KEY (country_code, state_province, city, gym_name)
);This example has four columns in the Primary Key clause. An interesting characteristic of Compound Keys is that only the first column is considered the Partition Key. There rest of the columns in the Primary Key clause are Clustering Keys.
Clustering Keys
Each additional column that is added to the Primary Key clause is called a Clustering Key. A clustering key is responsible for sorting data within the partition. In our example crossfit_gyms_by_location table, country_code is the partition key with state_province, city, & gym_name acting as the clustering keys. By default, the clustering key columns are sorted in ascending order.
Order By
What if I wanted to change the default sort order from ascending to descending? There is an additional WITH clause that you need to add to the CREATE TABLE to make this possible.
CREATE TABLE crossfit_gyms_by_location (
country_code text,
state_province text,
city text,
gym_name text,
PRIMARY KEY (country_code, state_province, city, gym_name)
) WITH CLUSTERING ORDER BY (state_province DESC, city ASC, gym_name ASC);Now we’ve changed the ordering of the Clustering Keys to sort state_province in descending order. Note, I did need to specify that city and gym_name is still in ascending order, even though it’s the default sort order. Did you notice that I did not specify what the sort is for country_code? Since it’s the partition key, there is nothing to sort as hashed values won’t be close to each other in the cluster.
Data Example
Let’s insert some sample data into this crossfit_gyms_by_location table to show how things will look like on disk. I’m sampling from the list of locations on Crossfit’s Affiliate List.
INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('USA', 'CA', 'San Francisco', 'San Francisco CrossFit');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('USA', 'CA', 'San Francisco', 'LaLanne Fitness CrossFit');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('USA', 'NY', 'New York', 'CrossFit NYC');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('USA', 'NY', 'New York', 'CrossFit Metropolis');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('USA', 'NV', 'Las Vegas', 'CrossFit Las Vegas');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('USA', 'NV', 'Las Vegas', 'Kaizen CrossFit');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('CAN', 'ON', 'Toronto', 'CrossFit Toronto');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('CAN', 'ON', 'Toronto', 'CrossFit Leslieville');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('CAN', 'BC', 'Vancouver', 'CrossFit Vancouver');INSERT INTO crossfit_gyms_by_location (country_code, state_province, city, gym_name) VALUES ('CAN', 'BC', 'Vancouver', 'CrossFit BC');Now we have some data to see what this all is doing. The first column, country_code has values of USA & CAN. Both will be hashed and stored in different partitions. The way that the rows are stored in those partitions will be dictated by the WITH CLUSTERING ORDER BY clause that we defined.
country_code | state_province | city | gym_name
--------------+----------------+---------------+--------------------------
CAN | ON | Toronto | CrossFit Leslieville
CAN | ON | Toronto | CrossFit Toronto
CAN | BC | Vancouver | CrossFit BC
CAN | BC | Vancouver | CrossFit Vancouver
USA | NY | New York | CrossFit Metropolis
USA | NY | New York | CrossFit NYC
USA | NV | Las Vegas | CrossFit Las Vegas
USA | NV | Las Vegas | Kaizen CrossFit
USA | CA | San Francisco | LaLanne Fitness CrossFit
USA | CA | San Francisco | San Francisco CrossFit
(10 rows)Composite Key
A Composite Key is when you have a multi-column Partition Key. The above example only used country_code for partitioning. This means that all records with a country_code value of “USA” are in the same partition. This can lead to wide-rows very quickly. There are just over 7,000 CrossFit gyms in the US alone. So by using that single column partition key, we have a row with over 7,000 combinations in that single partition.
Avoiding wide rows is the perfect reason to move to a Composite Key. Let’s change the Partition Key to include the state_providence & city columns. We do this by nesting parenthesis around the columns that are to be a Composite Key, as follows:
CREATE TABLE crossfit_gyms_by_location (
country_code text,
state_province text,
city text,
gym_name text,
PRIMARY KEY ((country_code, state_province, city), gym_name)
) WITH CLUSTERING ORDER BY (gym_name ASC);What this does is it changes the hash value from being calculated off of only country_code. Now it will be calculated off of the combination of country_code, state_province, & city. Now we aren’t sorting on those included columns. Each combination of the three columns have their own hash value and will be stored in completely different partition in the cluster.
Why & When to Use Different Key Types
I’ve shown you four different ways to use keys in table creations. But why would you want to use one over another? It all depends on the queries that you need to accommodate. With the topic of CrossFit gym locations, I can think of a couple different ways that I may want to search for a gym.
First example that comes to mind is, I know the name of the gym I’m needing more information on. I want to select from a table where the name equals that known gym name. This scenario would be ideal for a single column partition key.
Second example that comes to mind is, I’m traveling to a city and need to find a gym there to get my workout in at. I want to select from a table where I can specify the country, state, & city. I would expect a list of all the available gyms. This scenario is great for the Composite Key. It allows me to filter on the three parts in the key and Cassandra can quickly locate the information that I’m searching for.
Third example that comes to mind is, I’ve done the previous example and there aren’t any gyms in my city I’m looking for, so I need to only search on country and state, or maybe just country. This scenario is ideal for the wide row example where we have a single partition key, and a bunch of clustering keys for narrowing the results. I can select from a table where I know the country or where I know the country & state.
Summary
Choosing keys for your Cassandra tables can be tricky, but I hope to have helped shine some light on the details behind the decision. I covered what the different types of keys are, how they can be used, what their purpose is, and how they affect your queries. The following is a quick recap on the subject:
-
Primary Keys, also known as Partition Keys, are for locating your data to a partition in the cluster.
-
Compound Keys are for including other columns in the filter but not affecting the partition.
-
Clustering Keys are for sorting your data on the partition.
-
Composite Keys are for including more columns in the calculation of the partition value.
Now go out and design some tables with different keys. The best way to learn is trial and error. To read more, check out my post on Data Model Basics. Happy Data Modeling!