Backing Up Cassandra Data
The Apache distribution of Cassandra does not automatically take backups of it’s data. However, it does include a tool to create backups. Backups in Cassandra are called “snapshots”. In the photography sense of the word, a snapshot is a picture of what the data looks like at a moment in time. Since data in Cassandra is immutable, taking a snapshot is quick, painless, and has very little impact on the system.
This post will cover the following topics about backing up Cassandra data.
-
Cassandra Write Path
-
Taking a snapshot
-
Where snapshots are stored
-
Viewing snapshots
-
Naming a snapshot
-
Incremental snapshots
-
Removing snapshots
It will also cover a few recommended actions to do with snapshots.
-
Off-site snapshots
-
Data schema files
-
Global snapshots
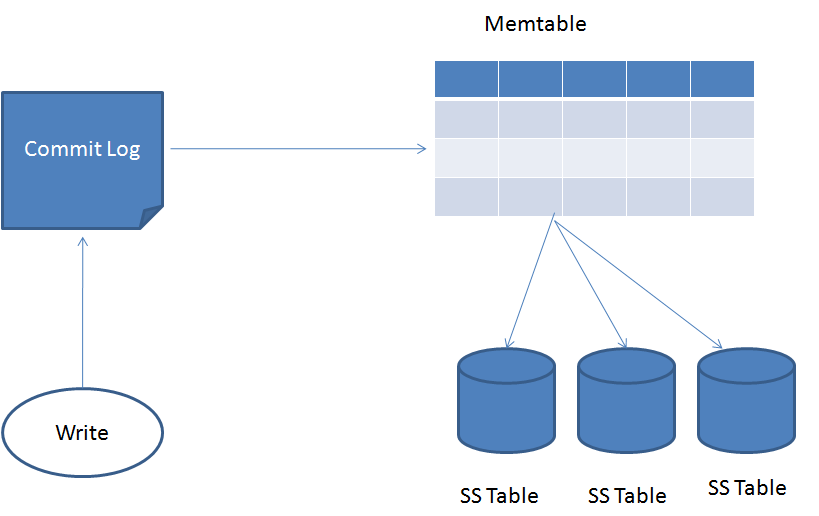
Cassandra Write Path
When Cassandra accepts a write operation, there is a path that every piece of data has to follow.
-
First, the data is appended to a Commit Log. The Commit Log is a sequential, memory-mapped log file that is a record of every insert/update/delete of data. It’s purpose is to be a durable, replayable list of actions to take if failure occurs.
-
Second, the data is written to a Memtable. Memtables are the mutable, in-memory organization that Cassandra uses to keep data cached. The MemTables can be rebuilt using the Commit Log if a crash happens before the MemTable is flushed to disk.
-
Last, when the Memtable fills up, the data is flushed to an immutable SSTable. SSTables are the data files on disk.
Taking a Snapshot
Snapshots are taken using the nodetool snapshot command. This a per node action, meaning that the command only takes a snapshot of the data on the node where it’s run.
When the snapshot command is run, nodetool does a couple things.
-
First, it performs a flush action. This flushes all the data that is currently in Cassandra’s memtables to disk.
-
Second, it creates a new snapshot directory and places hard-links of all of the SSTable data files in it. By default, the snapshot directory is given a name corresponding to the epoch timestamp at which it was taken. image::/images/cassandra-snapshot-1.png[]
The snapshot command also allows you to optionally specify a keyspace. This will target only the specified keyspace. image::/images/cassandra-snapshot-2.png[]
Where Snapshots are Stored
Cassandra’s main configuration file, cassandra.yaml, has an entry for data_file_directories. This specifies the directory location where table data (SSTables) is stored. Under this directory, a substructure of /keyspace/table/ is created. When a snapshot is taken, the process first appends a singleton /snapshot/ directory under the table path. For each snapshot taken, a new directory is created with either the epoch time or the snapshot label. It is here that the snapshot files are stored.
<data_directory_location/keyspace_name/table_name/snapshots/snapshot_name/*>
Viewing Snapshots
With the release of Cassandra 2.1, nodetool included a listsnapshots command. This command outputs all the snapshots

Naming a Snapshot
The snapshot command has a plethora of available parameters that can be passed to it. One of those parameters allows you to assign a label, or name, for the snapshot directory instead of using the default epoch value. This parameter is -t. Naming a snapshot can be very helpful for organization. Names could be formated as readable dates or as a before/after upgrade. It’s up to you how creative your applied name is.

Incremental Snapshots
A snapshot by default is the entire dataset on the node. In the cassandra.yaml configuration file, there is property, incremental_backups, that changes that behavior. By default this property is set to false. When you change the value to true, Cassandra will hard-link each flushed SSTable to a backups directory. Cassandra does not automatically clear incremental backup files. You will need to manage removing the hard-link files on your own, as there is no built-in tool to remove them.
Removing Snapshots
Cassandra does not automatically remove snapshot files. However, nodetool includes a command to do just that. By issuing a nodetool clearsnapshot command and passing in the name of the snapshot (name or epoch), it will request that the snapshot is removed. Note, that it may take a small amount of time to actually remove the files.

Recommendations
Off-site Snapshots
If the node becomes unreachable, you will want your backups saved to another location. This can be a cloud provider, or another location on your network. I tend to only keep the latest backup on the machine, and copy all other backups to an off-site cloud provider. By leaving the latest backup, it will save you some bandwidth/time if a problem arises and you need to recover some data.
Data Schema File
The data that being backed up does not retain what the schema looks like. So to prevent issues if you ever need to restore your data, it’s advisable that you create a text file with the schema at the time of snapshot. This can be done with a DESCRIBE SCHEMA command in CQL. Simply output this to a text file and save it with your snapshot files.
Global Snapshot
Running nodetool snapshot is only run on a single node at a time. This only creates a partial backup of your entire data. You will want to run nodetool snapshot on all of the nodes in your cluster. But it’s best to run them at the exact same time, so that you don’t have fragmented data from a time perspective. You can do this a couple of different ways. The first, is to use a parallel ssh program to execute the nodetool snapshot command at the same time. The second, is to create a cron job on each of the nodes to run at the same time. The second assumes that your nodes have clocks that are in sync, which Cassandra relies on as well.
Summary
In this post, I’ve covered most of the major aspects of performing backups on your Cassandra data. You should be able to successfully, both take and remove a named snapshot. As well as be able to turn on the incremental backup feature. Please do remember to follow our listed recommendations as well.